We built Truss because we were frustrated with the long feedback loops in ML model deployment. When you have to wait for your server to rebuild every time you make a change, iteration is painful.
Meanwhile, web developers have enjoyed live reload workflows for years, where changes are patched onto a running server and available almost instantly.
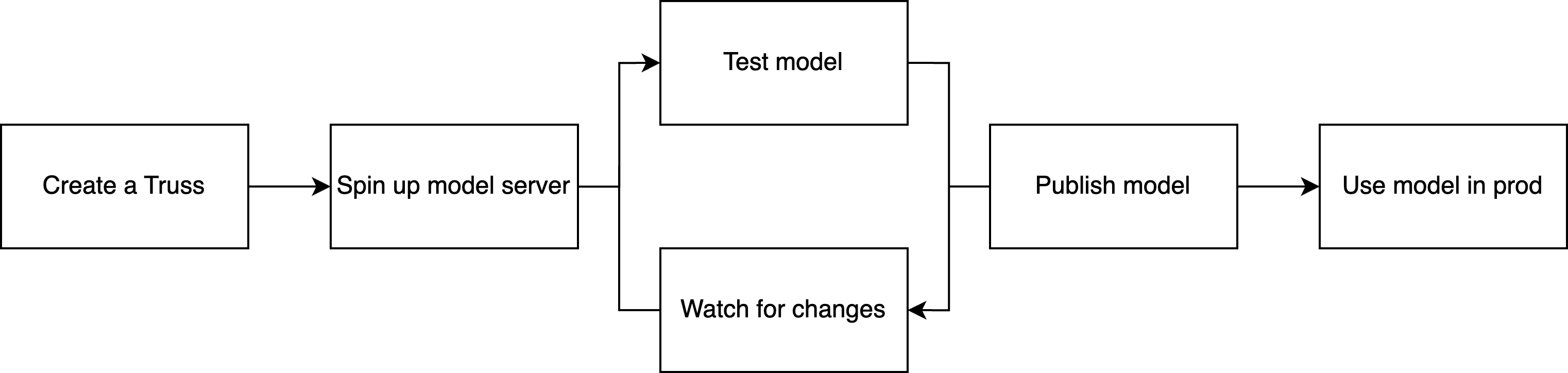
With Truss, you get the same live reload workflow for serving ML models.
Create a Truss
A Truss is an abstraction for a model server. But more literally, it’s a set of files. Running truss init creates those files in a target directory.
To package a model with Truss, follow the quickstart, a step-by-step example, or an example from GitHub.
See the CLI reference for more information on truss init.
Spin up model server
A model server takes requests, passes them through an ML model, and returns the model’s output. When you’re ready to start testing your Truss, use truss push to spin up a model server with your model and config.
See the CLI reference for more information on truss init.
Test the model
Once your model server is live, you can invoke your model with truss predict.
See the CLI reference for more information on truss predict.
Watch for changes
Run the truss watch command in a new terminal tab in the same working directory, as you’ll need to leave it running while you work.
truss watch running, it will automatically attempt to patch that change onto the model server. Most changes to model.py and config.yaml can be patched.
The following changes should not be made in a live reload workflow:
- Updates to
resources in config.yaml, which must be set before the first truss push
- Changes to the
model_name in config.yaml. Changing the model name requires a new truss push to create a new model server.
Publish your model
Once you’re happy with your model, stop truss watch and run:
This will re-build your model server on production infrastructure.
Use model in production
To invoke the published model, run:
With Baseten as your remote host, your model is served behind autoscaling infrastructure and is available via an API endpoint.